Unless a particular piece of content on the Web has some strict
access control policies, most users do not feel the need to check for
the license it is under and be license compliant. To verify this
hypothesis we conducted an experiment to assess the level of license
violations on the Web. Specifically, the goal of the experiment was to
obtain an estimation for the level of CC attribution license
violations on the Web using Flickr images.
The sampling method used for the experiment was simple random sampling on clusters of Web pages gathered during a particular time frame. To ensure a fair sample we used the Technorati blog indexer without hand-picking Web pages to compose the sample to check for attribution license violations. We limited the number of Web pages to around 70, and the number of images to less than 500, so that we could do a manual inspection to see if there are any false positives, false negatives and/or any other errors. This also enabled us to check if the different samples contained the same Web pages. We found that the correlation among the samples was minimal.
The Technorati blog indexer crawls and indexes blog-style Web pages and keeps track of what pages link to them, what pages they link to, how popular they are, how popular the pages that link to them are, and so on. Technorati data are time dependent, and therefore the Technorati Authority Rank, a measurement that determines the top "n" results from any query to the Technorati API, is based on the most recent activity of a particular Web page. We actually expected that the use of the Technorati Authority Rank would introduce a bias in our sample. This is because the top Web pages from the Technorati blog indexer are probably well visited, hence more pressure on the Web page owners to fix errors in attribution. However, the results proved otherwise!.
The Technorati Cosmos querying functions allow the retrieval of
results for blogs linking to a given base URI based on the authority
rank. Therefore to generate the samples, we used the Technorati Cosmos
functions by retrieving results for Web pages linking to Flickr server
farm URIs that have this particular format:
http://farm<farm-id>.static.flickr.com/<server-id>/<id>_<secret>.(jpg|gif|png)(According to http://www.flickr.com/services/api/misc.urls.html, all Flickr images have that particular URI pattern).
Flickr is still using the older CC 2.0 recommendation. Therefore, Flickr users do not have that much flexibility in specifying their own attributionURL or the attributionName as specified in ccREL. However, it is considered good practice to give attribution by linking to the Flickr user profile or by giving the Flickr user name (which could be interpreted as the attributionURL and the attributionName respectively), or at least, point to the original source of the image. Therefore, the criteria for checking attribution consist of looking for the attributionURL or the attributionName or any source citations within a reasonable level of scoping from where the image is embedded in the Document Object Model (DOM) of the corresponding Web page.
Here are the results from the experiment conducted to check how much CC-BY (attribution) license violations on Flickr images are there on the Web. The code used to run the experiment can be found here.
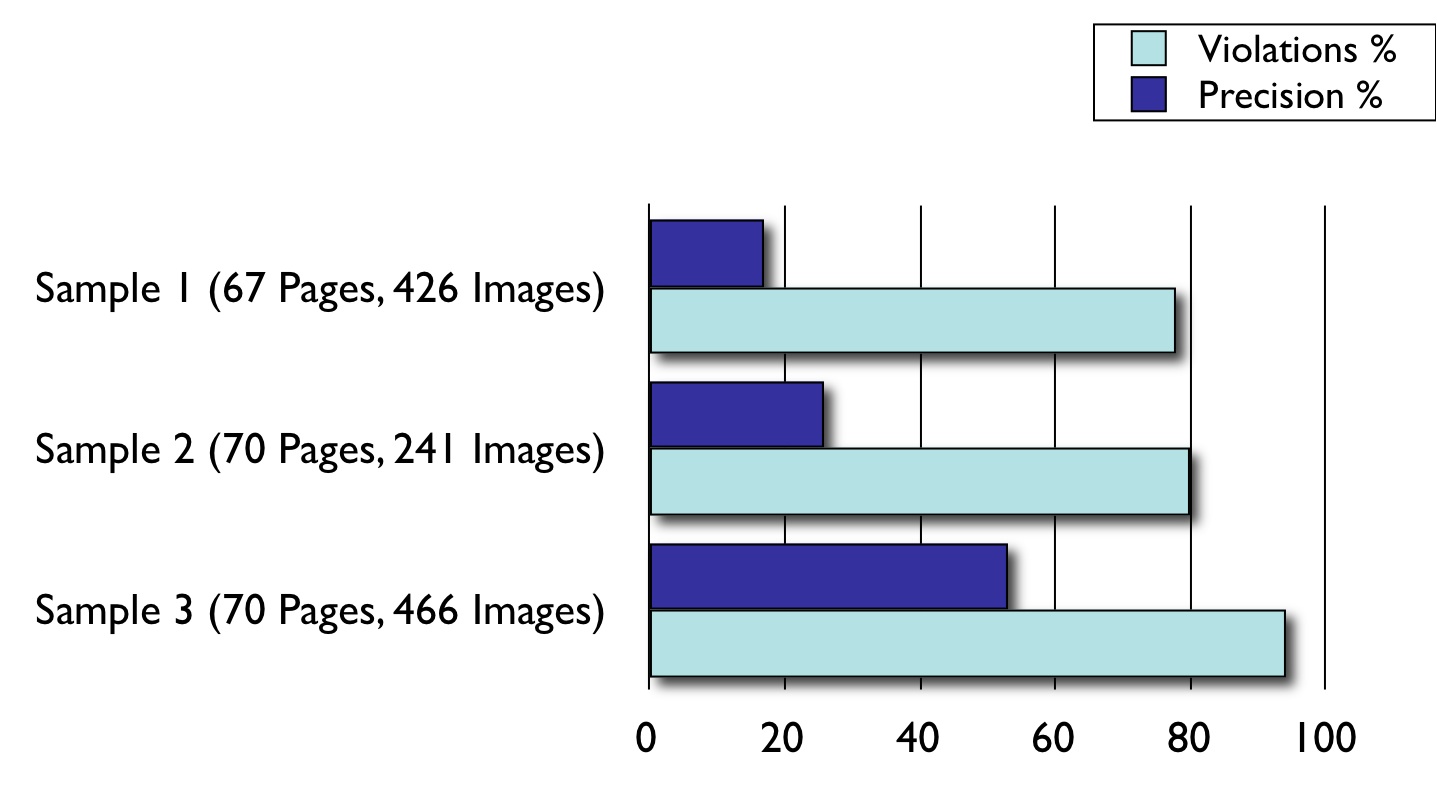
Here is a summarized view of the results:
These results have misattribution and non-attribution rates ranging from 78% to 94% signaling that there is a strong need to promote license or policy awareness among reusers of content. The entire result set includes the total number of Web pages tested, number of images in all of those Web pages, number of properly attributed images, number of misattributed or non-attributed images, and the number of instances that led to an error due to parsing errors resulting from bad HTML. Using these values, the percentages of misattribution and non-attribution for each sample were calculated.
For example, consider the case where a user uploads her photos on Flickr, and uses those photos in one of her own Web pages without attributing herself. As the copyright holder of the work, she can do pretty much whatever she wants with those, even though the CC BY license deed states: "If You Distribute you must keep intact all copyright notices for the Work and provide (i) the name of the Original Author...". However if she fails to include the license notice and the attribution to herself, she may be setting a precedent for the violation of her own rights in the long run. From the point of view of the experiment, it was difficult to infer the page owner from the data presented in the page. Even if that was possible, it is hard to make a correlation between the Flickr photo owner and the page owner. However, we manually inspected the samples to see whether the misattributed images were actually from the user or not, and flagged the ones which are definitely from the original user as false positives in the results set to obtain the precision rate. After this correction, we found the precision rate of the experiment to be between 55% to 40%.
We found out that a majority of the Web pages examined in this experiment have not used ccREL in marking up attribution. Therefore, we used a heuristic to check for the existence of attribution in the pages used in the trials. This heuristic includes the attributionName constructed from the Flickr user name, or the attributionURL constructed from the Flickr user profile URI, or the original source document's URI. We expected to find the attribution information in the parent of the DOM element or in one of the neighboring DOM elements. This can be visually correlated to finding the attribution information immediately after the content that is being reused. However, since there is no strict definition from CC as to how attribution should be scoped, someone could also attribute the original content creator somewhere else in the document. However, considering that it is possible the user intended to include more than one image from the same original content creator, and by mistake failed to attribute some images, while correctly attributing all the others, we only checked attribution information within the neighboring DOM elements, and not at the document level.
Use of such blog aggregators (for example tumblr.com) is another problem in getting an accurate assessment of attribution license violations. For example, in a blog post where a photo was reused, the original owner of the photograph may have been duly attributed. But when the tumble-log pulls in the feed from that post in the original Web page and presents the aggregated content, the attribution details may be left out. This problem is difficult to circumvent because there is no standard that specifies how aggregation should take license and attribution details into consideration.